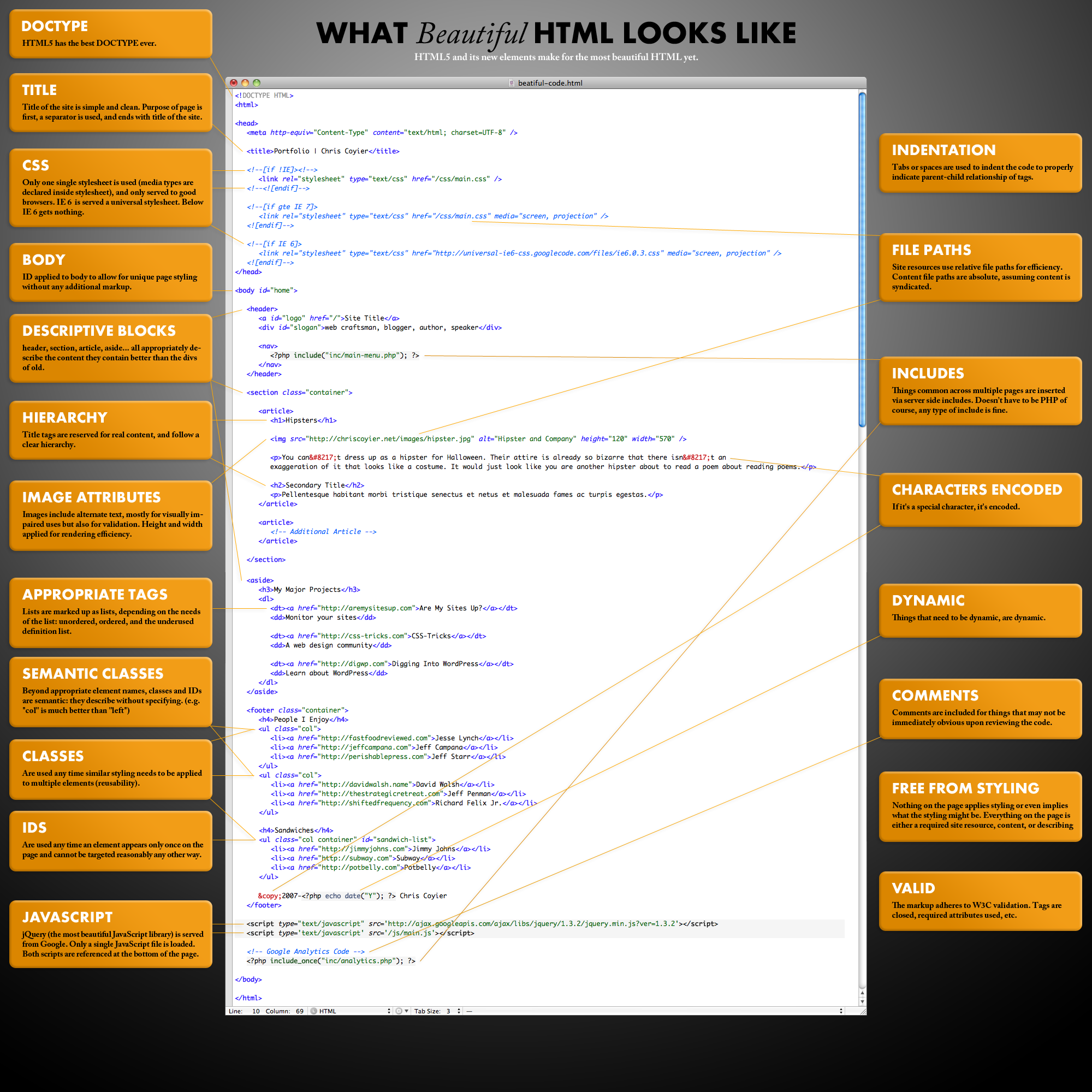
当我开始从事网页开发时(2005-2010 年对我来说是形成性时期),我学到的第一个教训之一就是拥有一个干净的 HTML 基础。 “什么是漂亮的 HTML 代码” 实际上是这个网站上最受欢迎的文章之一。 那篇文章中的图片 不时地出现在 subreddits 的热门页面上。
{kind=link}
现在,虽然我在为像这个网站这样的网站工作时通常仍然以这种方式默认编写 HTML,但我也会处理一些根本没有这种 HTML 输出的项目。我不在 Twitter 工作,但以下是你打开 DevTools 并检查那里 DOM 时可能会看到的内容

没有人会指责那是“干净”的 HTML。事实上,不难想象会有人批评它。为什么所有的 divs! divitis!! 这真的只是一个 <div role="button">,拜托。 这些是糟糕的类名!机器人呕吐物!
更接近真相的可能是,它实际上并不那么重要。这不是语义不重要。这不是可访问性不重要。这不是性能不重要。而是这个输出实际上做得很好,或者至少和他们想要做的那样好。
React Native for Web 提供跨平台基本元素,这些元素可以规范不一致并允许构建网络应用程序,这些应用程序除了其他功能之外,还具有触摸友好性。
在不熟悉该框架的人眼中,React Native for Web 生成的 HTML 可能看起来非常丑陋,充满了糟糕的实践。
该 DOM 实际上确实生成了一个预期且可用的可访问性树。带有角色的 <div> 用于克服某些跨平台样式限制。这些类来自一个样式框架,该框架有助于 CSS 范围。它看起来很古怪,但这一切都是有原因的。
这并不是说所有这些都高于批评。你可以争辩说,机器人类名不允许用于辅助可访问性的用户样式表。你可以争辩说,多余的 divs 会导致 DOM 不必要地变重。你可以争辩说,发布机器人呕吐物会使网络变得不那么容易学习,尤其是在没有 源映射 的情况下。
有一些事情可以谈论,但仅仅看到一堆带有奇怪类名的 divs 并不意味着它是糟糕的代码。而且它也不限于 React Native,许多框架在他们实际向浏览器提供的代码中都有自己的特殊扭曲,而这几乎总是为了让网站以某种方式更好地工作,而不是为了教学或可读性。
这种标记存在一个非微不足道的理由,那就是这种标记实际上使得通过 lxml 或 Beautiful Soup 等库进行程序化抓取变得困难。
这将 Twitter 的“数据收集用例”从网络转移到 Twitter API,在那里 Twitter 可以更轻松地控制速率和访问。任务完成。
这是一种防止抓取器的保护措施。我尝试使用过一个,但无法让它正常工作。
这确实是这种“机器人”DOM 结构背后的原因。关于这篇文章本身,除了安全通过模糊(防止抓取器)之外,没有理由不构建一个轻量级且快速的网络应用程序。你不需要任何类型的混淆来使其在触摸设备上更好地工作,这没有道理!
但这对抓取器没有帮助,因为在那个嵌套地狱的底部,有一个
<article>。它的结构非常静态,因此抓取器可以很好地遍历它。