随着比特币价格最近突破 20,000 美元,并进一步突破 30,000 美元,我认为深入探讨创建以太坊应用程序的价值。以太坊,如你所知,是一个公共(意味着对所有人开放,无限制)区块链,它充当分布式共识和数据处理网络,数据以“交易”(txns)的规范形式存在。但是,以太坊的当前功能只能存储(受 gas 费限制)和处理(受区块大小或参与共识的各方大小限制)有限的交易和交易/秒。现在,由于这是一篇关于使用 Redwood 和 Fauna 进行构建的“如何”文章,而不是关于“如何[… ]”的文章,我将不再深入探讨以太坊的工作原理、其限制及其没有限制等等的技术细节。相反,我将假设你,作为读者,已经对以太坊以及如何构建或使用它有一定的了解。
我意识到,有些没有以太坊经验的新手会偶然发现这篇文章,而我会指导这些用户一些方向。值得庆幸的是,截至重写本文时,以太坊最近更新了其开发者页面,其中包含大量资源和教程。我强烈建议新手学习一下!
不过,在接下来的过程中,我会提供相关的具体细节,以便任何熟悉构建以太坊应用程序、Redwood.js 应用程序或依赖 Fauna 的应用程序的人都可以轻松地遵循本教程中的内容。言归正传,让我们深入了解吧!
准备工作
该项目是对Emanator 单体仓库的派生,该项目由应用程序的创建者之一 Patrick Gallagher 在其团队的 Superfluid 黑客松提交的博客文章中进行了很好的描述。Patrick 的应用程序使用 Heroku 作为数据库,而我将展示如何在这个相同的应用程序中使用 Fauna!
由于该项目是派生项目,请确保在继续之前已下载MetaMask 浏览器扩展。
Fauna
Fauna 是一个 Web 原生 GraphQL 接口,支持自定义业务逻辑和与无服务器生态系统的集成,使开发人员能够简化代码并更快地发布。其底层的全球分布式存储和计算架构快速、一致且可靠,具有现代的安全基础设施。Fauna 非常易于上手,并提供 100% 的无服务器体验,无需管理。
Fauna 还为我们提供了一个高可用性解决方案,每个全球部署的服务器都包含我们数据库的一部分,并通过每个请求异步复制我们的数据,提供我们数据库或所执行交易的副本。
使用 Fauna 的一些好处可以概括如下:
- 事务性
- 多文档
- 地理分布式
简而言之,Fauna 使开发人员不必担心单文档或多文档解决方案。它保证数据一致性,而无需开发人员承担如何对系统进行建模以避免一致性问题的负担。要更好地了解 Fauna 如何做到这一点,请参阅这篇关于 FaunaDB 分布式事务协议的博客文章。
除了使用 Fauna,还可以选择其他一些替代方案,例如:
- Firebase
- Cassandra
- MongoDB
但这些选项无法像 Fauna 那样提供 ACID 保证,从而损害可扩展性。ACID 代表:
- **原子性:**所有交易都是一个单一的真相单元,要么全部通过,要么全部失败。如果我们在同一个请求中有多个交易,那么要么两个都成功,要么两个都失败,不能一个成功而另一个失败。
- **一致性:**交易只能将数据库从一个有效状态转换为另一个有效状态,即写入数据库的任何数据都必须符合数据库设定的规则,这确保所有交易都是合法的。
- **隔离性:**执行或创建交易时,并发交易会使数据库状态保持与顺序执行每个请求时相同的状态。
- **持久性:**任何执行并提交到数据库的交易都将持久保存到数据库中,无论系统停机或失败。
Redwood.js
由于我已经多次使用 Fauna,我可以亲身体验 Fauna 数据库,在所有我喜欢它的功能中,我最喜欢的是它使用起来多么简单易懂!不仅如此,Fauna 也很适合与 GraphQL 和 GraphQL 工具(如 Apollo Client 和 Apollo Server)配对!但是,我们不会直接使用 Apollo Client 和 Apollo Server。相反,我们将使用 Redwood.js,一个预先打包了 Apollo Client/Server 的完整堆栈 JavaScript/TypeScript(尚未投入生产)无服务器框架!
你可以在其网站和GitHub 页面上查看 Redwood.js。
Redwood.js 是一个从幕后诞生的新框架(哈哈),由 Tom Preston-Werner(GitHub 的创始人之一)创建。尽管如此,请注意,这是一个有意见的 Web 应用程序框架,为你做出了许多开发环境决策。虽然有些人可能不喜欢这种方法,但它确实为我们提供了一种更快的构建以太坊应用程序的方法,而这正是这篇文章的重点。
Superfluid
使用以太坊应用程序的挑战之一是区块确认。区块确认的对应物是交易确认(即数据),而确认需要时间,这意味着用户必须等待一段时间(通常为几分钟),直到他们发起的计算(无论是通过 UI 直接发起还是通过其他智能合约间接发起)被认为是真实或可信的。Superfluid 是一种协议,旨在通过引入现金流或交易流来解决这个问题,从而实现实时金融应用程序;也就是说,用户不再需要等待交易确认,可以立即执行下一组计算操作。
阅读 Superfluid 的文档以了解更多关于 Superfluid 的信息。
Emanator
Patrick 的团队做了一些非常酷的事情,将 Superfluid 的流式功能应用于 NFT,允许用户“铸造持续供应的 NFT”。然后可以通过拍卖出售这些 NFT 流。Emanator 应用程序另一个有趣的部分是,这些 NFT 是为创作者、艺术家 👩🎨 或音乐家 🎼 设计的。
关于该应用程序的运作方式还有更多技术细节,例如使用 Superfluid 即时分配协议 (IDA)、每次拍卖的收益分配、拍卖流程以及智能合约本身;但是,由于这是一个“如何”而不是“如何 [… ]”教程,我将为你提供原始Emanator `monorepo` 的 README.md 链接,如果你想了解更多信息。
最后,让我们来写一些代码!
设置
1. 从 `redwood-eth-with-fauna` 下载仓库
在你的终端、喜欢的文本编辑器或 IDE 中使用 Git 克隆`redwood-eth-with-fauna` 仓库。为了更好地理解,我将在这个教程中使用 VSCode。
2. 安装应用程序依赖项并设置环境变量 🔐
克隆仓库后,要安装该项目的依赖项,只需运行
yarn…在目录的根目录下。然后,我们需要从我们的 `.env.example` 文件中获取我们的 `.env` 文件。要做到这一点,请运行
cp .env.example .env在你的 `.env` 文件中,你还需要提供 `INFURA_ENDPOINT_KEY`。与你最初的想法可能不同,该变量实际上是你 Infura 应用程序的 `PROJECT ID`。
如果你没有 Infura 帐户,可以免费创建一个!🆓 🕺

这是我的 `redwood-eth-with-fauna` 应用程序的 Infura 仪表板示例视图。复制 `PROJECT ID` 并将其粘贴到你的 `.env` 文件中,用于 `INFURA_ENDPOINT_KEY`
3. 更新 GraphQL 模式并运行数据库迁移
在位于
api/prisma/schema.prisma …处的模式文件中,我们需要在 Auction 模型中添加一个字段。这是由于代码中的一个错误,导致该字段实际上在单体仓库中丢失了。因此,我们必须添加它才能使应用程序正常工作!

我们在第 33 行添加了一个名为 `contentHash` 的字段,类型为 `String`,这样我们的拍卖就可以添加到我们的数据库中,然后显示给用户。
接下来,我们需要使用 Redwood.js 命令运行数据库迁移,该命令将自动更新我们项目中的一些代码。(Redwood 开发人员为我们抽象了这项责任,真是太慷慨了;这个命令非常有效!)为此,请运行
yarn rw db save redwood-eth-with-fauna && yarn rw db up如果此过程成功,您应该会看到类似以下内容。

此时,您可以通过运行以下命令启动应用程序
yarn rw dev…并创建第一个 NFT,然后铸造它!🎉 🎉
注意:铸造新的 NFT 时,您可能会遇到以下错误

如果出现这种情况,只需刷新页面即可在右侧看到您的新 NFT!
您还可以点击新 NFT 的名称以查看其拍卖详细信息,如下所示

您还可以在终端中注意到,当您导航到此页面时,Redwood 会更新 API 解析器。
设置就完成了!不幸的是,我不会讲解如何使用 UI 的这一部分,但欢迎您访问 Emanator 的 monorepo 以了解更多信息。
现在,我们要将 Fauna 添加到应用程序中。
添加 Fauna
在将 Fauna 添加到 Redwood 应用程序之前,请确保通过按下 CTL+C(在 macOS 上)将其关闭。Redwood 为我们处理热重载,并将自动重新渲染页面,以便我们进行编辑,这在进行调整时可能会很烦人。因此,现在我们将关闭应用程序,直到完成添加 Fauna。
接下来,我们需要确保从 Fauna 仪表板创建的 Fauna 数据库中获取一个 Fauna 秘密 API 密钥(我不会讲解如何操作,但这篇 有用的文章很好地介绍了这一过程)。复制密钥秘密后,将其粘贴到 .env 文件中,替换 <FAUNA_SECRET_KEY>

请确保保留引号!
将 GraphQL 架构导入 Fauna
要将项目的 GraphQL 架构导入 Fauna,我们需要先手动将 3 个独立的架构缝合在一起。创建一个新的文件 api/src/graphql/fauna-schema-to-import.gql。在此文件中,我们将添加以下内容
type Query {
bids: [Bid!]!
auctions: [Auction!]!
auction(address: String!): Auction
web3Auction(address: String!): Web3Auction!
web3User(address: String!, auctionAddress: String!): Web3User!
}
# ------ Auction schema ------
type Auction {
id: Int!
owner: String!
address: String!
name: String!
winLength: Int!
description: String
contentHash: String
createdAt: String!
status: String!
highBid: Int!
generation: Int!
revenue: Int!
bids: [Bid]!
}
input CreateAuctionInput {
address: String!
name: String!
owner: String!
winLength: Int!
description: String!
contentHash: String!
status: String
highBid: Int
generation: Int
}
# Comment out to bypass Fauna `Import your GraphQL schema' error
# type Mutation {
# createAuction(input: CreateAuctionInput!): Auction
# }
# ------ Bids ------
type Bid {
id: Int!
amount: Int!
auction: Auction!
auctionAddress: String!
}
input CreateBidInput {
amount: Int!
auctionAddress: String!
}
input UpdateBidInput {
amount: Int
auctionAddress: String
}
# ------ Web3 ------
type Web3Auction {
address: String!
highBidder: String!
status: String!
highBid: Int!
currentGeneration: Int!
auctionBalance: Int!
endTime: String!
lastBidTime: String!
# Unfortunately, the Fauna GraphQL API does not support custom scalars.
# So, we'll this field from the app.
# pastAuctions: JSON!
revenue: Int!
}
type Web3User {
address: String!
auctionAddress: String!
superTokenBalance: String!
isSubscribed: Boolean!
}使用此架构,我们现在可以将其导入 Fauna 数据库。
此外,不要忘记对 3 个独立的架构文件 api/src/graphql/auctions.sdl.js、api/src/graphql/bids.sdl.js 和 api/src/graphql/web3.sdl.js 进行必要的更改,使其与新的 Fauna GraphQL 架构相对应!这对于保持应用程序的 GraphQL 架构和 Fauna 的 GraphQL 架构之间的一致性非常重要。
查看完整项目差异 - 快速入门部分
如果您想深入了解并学习使该项目正常运行所需的必要更改,那太棒了!请转到下一部分!
否则,如果您只想快速上手,本部分适合您。
您可以在项目的存储库根目录中签出 integrating-fauna 分支。为此,请运行以下命令
git checkout integrating-fauna然后,再次运行 yarn,以进行完整性检查
yarn要启动应用程序,您可以运行以下命令
yarn rw dev添加 Fauna 的步骤
现在,我们还需要执行一些其他步骤才能启动项目!
1. 安装 faunadb 和 graphql-request
首先,让我们安装 Fauna JavaScript 驱动程序 faunadb 和 graphql-request。我们将在这两个驱动程序的帮助下,对数据库脚本文件夹进行主要的修改,以便添加 Fauna。
要进行安装,请运行
yarn workspace api add faunadb graphql-request2. 编辑 api/src/lib/db.js 和 api/src/functions/graphql.js
现在,我们将使用 Fauna 实例替换 api/src/lib/db.js 中的 PrismaClient 实例。您可以删除文件中的所有内容,并用以下内容替换:

然后,我们需要对 api/src/functions/graphql.js 文件进行一些小更新,如下所示:

3. 创建 api/src/lib/fauna-client.js
在这个简单的文件中,我们将使用两个变量实例化 Fauna 数据库的客户端实例,这些变量将在下一步中使用。此文件最终应如下所示:

4. 更新 api/src/services/auctions/auctions.js 下的第一个服务
现在是比较困难的部分。为了使服务正常运行,我们需要将所有与 Prisma 相关的命令替换为使用 Fauna 客户端实例的命令,该实例是我们刚刚创建的 fauna-client.js 文件中的实例。这部分一开始看起来并不直观,但经过仔细思考,所有必要的更改都归结为理解 Fauna 的 FQL 命令的工作原理。
FQL(Fauna 查询语言)是 Fauna 用于查询 Fauna 的本机 API。由于 FQL 是“表达式导向的”,因此使用它就像链接几个函数命令一样简单。因此,对于 api/services/auctions/auctions.js 中的第一个更改,我们将执行以下操作:

简单解释一下,首先,我们从正确的项目文件路径中导入客户端变量和 db 实例。然后,我们删除第 11 行,并用第 13-28 行替换(目前可以忽略注释,但如果您真的想查看这些注释的其余部分,可以签出该项目的存储库中的 integrating-fauna 分支,以查看完整的差异)。在这里,我们所做的只是使用 FQL 查询 Fauna 索引中的拍卖索引,以从 Fauna 数据库中获取所有拍卖数据。您可以通过运行 console.log(auctionsRaw) 来测试这一点。
通过运行该 console.log(),我们发现我们需要进行一些对象解构,才能获取更新先前第 18 行所需的数据
const auctions = await auctionsRaw.map(async (auction, i) => {由于我们正在处理对象,但想要一个数组,因此我们将添加以下内容,在完成 const auctionsRaw 的声明后将其添加到下一行

现在,我们可以看到我们获得了正确的数据格式。
接下来,让我们将 auctionsRaw 的调用实例更新为新的 auctionsDataObjects

现在是更新此文件中最具挑战性的部分。我们想要更新 auction 和 createAuction 函数的简单 return 语句。实际上,我们所做的更改非常相似。因此,让我们更新 auction 函数,如下所示:

同样,您可以忽略注释,因为此注释只是为了说明在更改之前存在的首选 return 命令语句。
这个查询的意思是,“在拍卖集合中,查找一个具有此地址的特定拍卖”。
完成此 createAuctin 函数的下一步相当hacky。在制作本教程时,我意识到 Fauna 的 GraphQL API 不支持自定义标量(您可以在 其 GraphQL 文档的“限制”部分 中阅读有关此问题的更多信息)。不幸的是,这意味着 Emanator 的 monorepo 的 GraphQL 架构无法开箱即用。最终,这导致不得不进行许多细微的更改,才能使应用程序能够正确运行拍卖的创建。因此,与其详细讲解这一部分,我将首先向您展示差异,然后简要总结更改的目的。

查看第 100 和 101 行的绿色行,我们可以看到这里使用的函数命令并没有太大区别;这里,我们只是在拍卖集合中创建了一个新文档,而不是从索引中读取数据。
回到此 createAuction 函数的数据字段,我们可以看到我们得到了一个 input 作为参数,实际上指的是主页上新 NFT 拍卖表单的 UI 输入字段。因此,input 是一个包含六个字段的对象,即 address、name、owner、winLength、description 和 contentHash。但是,完成拍卖类型的 GraphQL 架构所需的另外四个字段仍然缺失!因此,我创建的其他变量 id、dateTime、status 和 highBid 是我或多或少硬编码的变量,以便此函数能够成功完成。
最后,我们需要完成 Auction 常量的导出。为此,我们将再次使用 Fauna 客户端进行以下更改

我们终于完成了第一个服务 🎊 ,真是太棒了!
完成 GraphQL 服务
到目前为止,您可能已经厌倦了更新 GraphQL 服务的这些更改(我知道我在尝试学习必要的更改时感到很疲倦!)。因此,为了节省您将此应用程序正常运行的时间,我将与您分享 integrating-fauna 分支中的 git 差异,我已经在存储库中对其进行了正常运行。分享完后,我将总结所做的更改。
要更新的第一个文件是 api/src/services/bids/bids.js

最后,更新我们最后的 GraphQL 服务
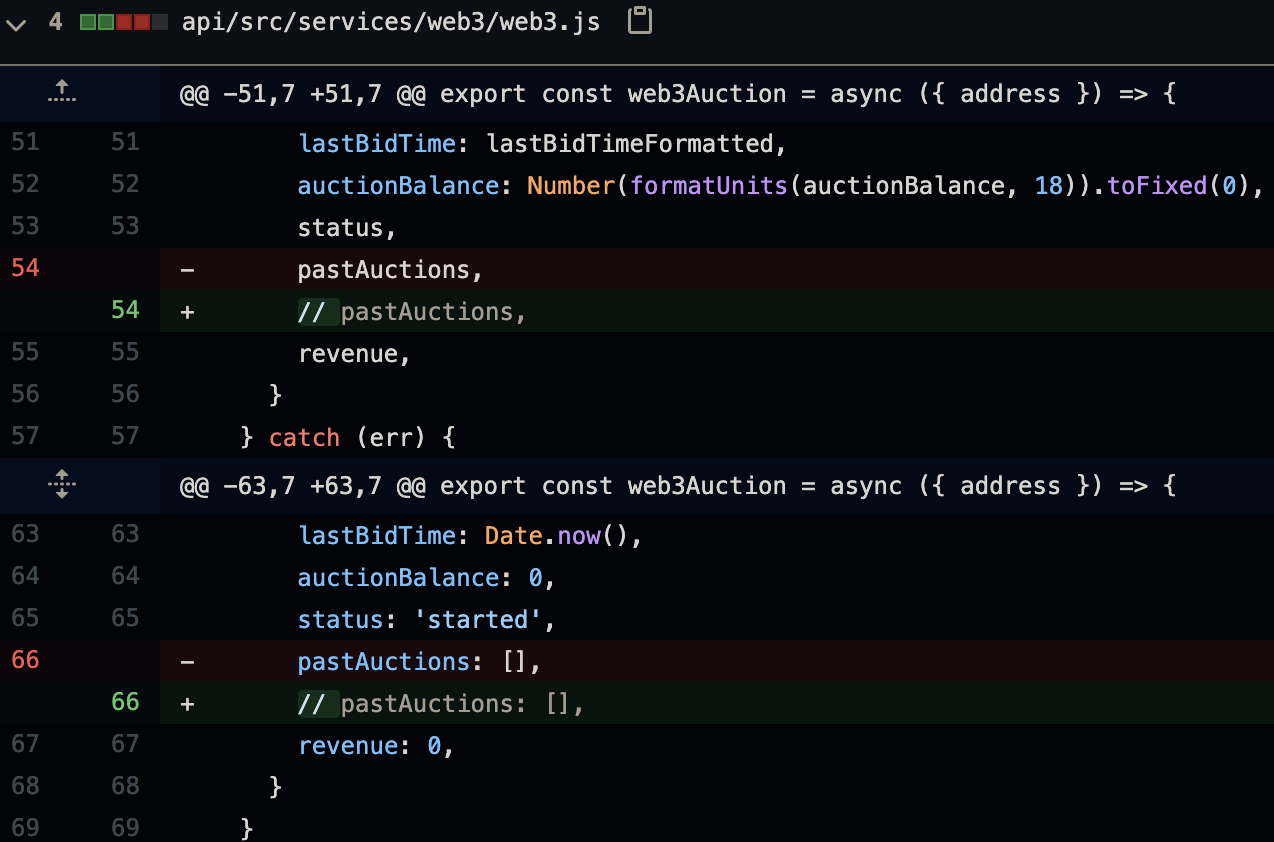
最后,web/src/components/AuctionCell/AuctionCell.js 中还需要进行一项更改

因此,回到 Fauna 不支持自定义标量的问题。由于 Fauna 不支持自定义标量,因此我们不得不从 web3.js 服务查询中注释掉 pastAuctions 字段(以及将其从我们的 GraphQL 架构中注释掉)。
在 web/src/components/AuctionCell/AuctionCell.js 中进行的最后一次更改是另一个权宜之计,目的是使新创建的 NFT 地址域名(您可以在创建新的 NFT 后,点击主页右侧 NFT 名称的超链接,导航到这些域名)可点击,而不会抛出错误。😄
结论
最后,当您运行
yarn rw dev...并创建新的代币时,您现在可以使用 Fauna 来完成!🎉🎉🎉🎉
最终说明
有两个注意事项。首先,您将在创建 NFT 并使用 MetaMask 确认交易后,在创建 NFT 表单上方看到此烦人的错误消息。

不幸的是,除了刷新页面,我找不到解决此问题的方法。因此,我们将像我们最初的 Emanator 单体仓库版本一样进行操作。
但是,当您刷新页面时,您应该会看到您的新代币显示在右侧!👏

而且,这是使用从 Fauna 获取的 NFT 代币数据!🙌 🕺 🙌🙌
第二个注意事项是,由于 web/src/components/AuctionCell/AuctionCell.js 中的错误,新 NFT 的页面仍然无法渲染。
这是我无法解决的另一个问题。但是,您可以在这里发挥作用!此仓库 redwood-eth-with-fauna 在 GitHub 上公开提供,以及(目前)最终的 integrating-fauna 分支,其中包含一个工作(如目前工作😅)的 Emanator 应用程序版本。因此,如果您对该应用程序真的很感兴趣,并且想探索如何使用 Fauna 进一步利用该应用程序,请随时分叉该项目并进行探索或更改!您随时可以在 GitHub 上联系我,我很乐意帮助您!😊
本教程就到这里,希望您喜欢!如果您有任何问题,请随时在 GitHub 上联系我!